AI Agent 跑到一半沒 token 了 — token budget 問題沒人在講,但很重要
2026年7月4日 · Waiting7777 · 7 分鐘閱讀
AI AgentsLLMAItokenizersystem prompttoken budgetagentic workflow實戰問題Agent 跑到一半沒 token 了,這才是真正的問題
> Meta Shift
我認為 token budget 是目前 agentic AI 落地最被低估的技術問題之一,沒有之一。
大家在聊 AI agent 的時候,焦點永遠放在模型夠不夠聰明、context window 夠不夠大、tool use 夠不夠穩。但 Matan Grinberg(Factory 共同創辦人兼 CEO)點出了一個更基礎、更務實的問題:一個 agent 執行複雜任務,要怎麼控制它的 token 消耗?
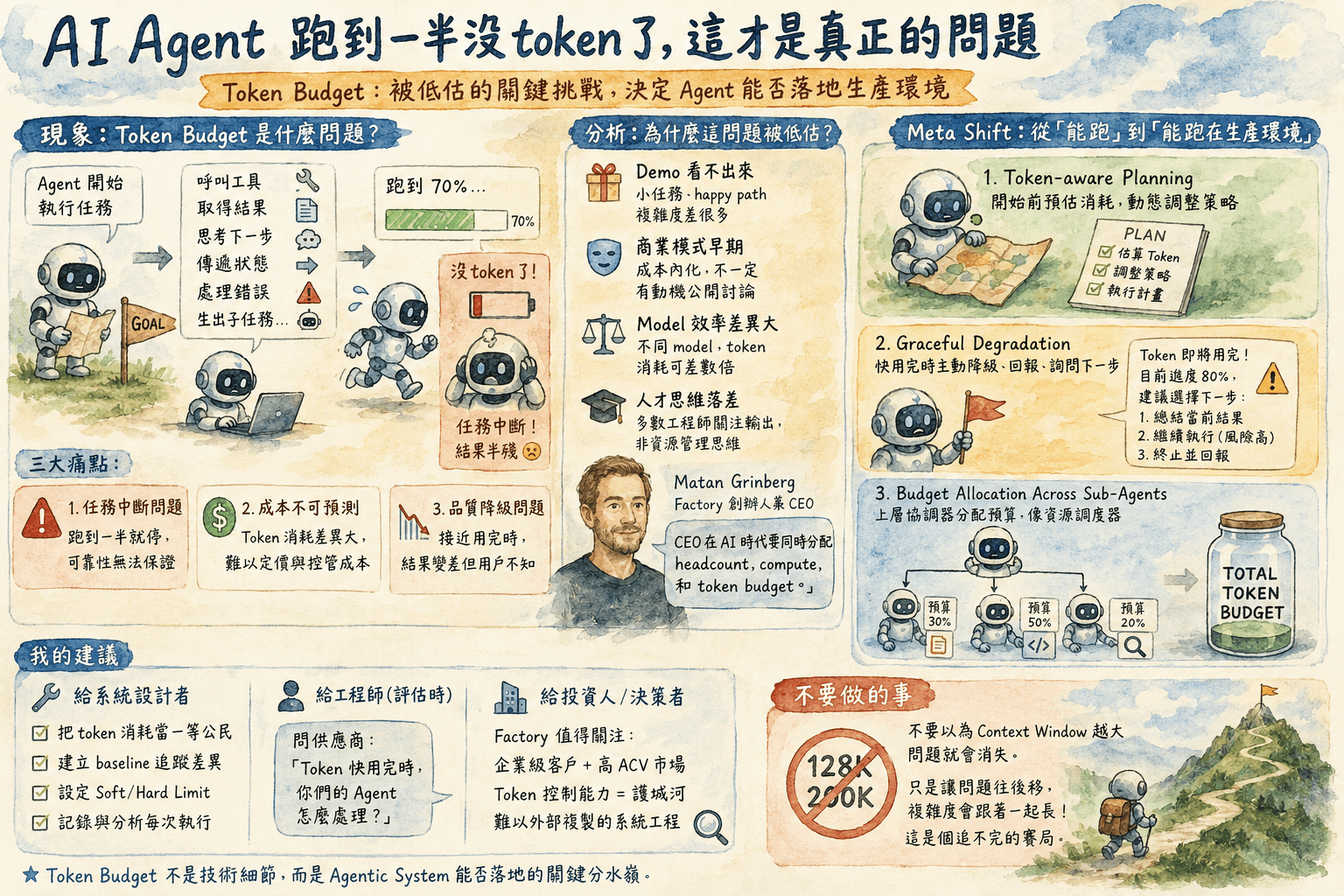
這問題聽起來很無聊,但你只要真的跑過複雜的 agentic workflow 就知道有多痛。任務跑到 70%,token 用完了,agent 自己也不知道怎麼收尾,然後你拿到一個半殘的結果,要嘛花更多錢重跑,要嘛手動接管收拾爛攤子。
Factory 目前估值 $1.5 billion,客戶包含 Nvidia、Morgan Stanley、Adobe,是真的在企業環境把 AI agent 跑起來的公司(來源:The Generalist)。Matan 從這個角度講 token budget,不是學術討論,是踩坑踩出來的實戰經驗。
現象:token budget 在 agentic workflow 裡是什麼問題
要理解這個問題,先搞清楚 agentic workflow 跟一般 LLM 呼叫的差異。
你問 ChatGPT 一個問題,它吐一段文字給你,這是一次 inference,token 消耗是線性的、可預測的。但 agent 不一樣,它會:
- 呼叫 tool、拿回結果、再丟進 context 繼續想
- 在 subtask 之間傳遞中間狀態
- 遇到錯誤的時候 retry 或換策略
- 有時候還會生出更多 sub-agent 去做子任務
每一步都在消耗 token,而且消耗量在任務開始前很難精確預估。一個軟體開發任務,可能因為 codebase 複雜度、bug 的深度、需要讀幾個文件,導致最後的 token 消耗差個 3 到 10 倍都不奇怪。
Matan 在訪談裡把這個問題定位成 resource allocation problem——CEO 在 AI 時代面臨的挑戰,不再只是分配人力,而是同時要分配 headcount、compute 和 token budget(來源:The Generalist,timestamp 11:58)。這三個維度的 tradeoff 在傳統 IT 管理裡根本不存在,但現在是真實的決策問題。
具體的痛點有三個:
1. 任務中斷問題 Agent 跑到一半 context window 塞滿或 budget 耗盡,任務就斷在那裡。對企業來說,這不只是重跑的成本,而是工程流程的可靠性問題。你沒辦法把一個會隨機失敗的工具交給生產環境。
2. 成本不可預測 如果一個 agent workflow 的 token 消耗可以差到 10 倍,你根本無法給企業客戶報一個合理的 pricing。要嘛你收很多、要嘛你虧很多,兩個都不對。
3. 品質降級問題 有些 agent 在快用完 token 的時候會開始走捷徑——skip 一些驗證步驟、輸出比較簡略的結果、或直接截斷回應。這種 degradation 通常是靜默的,使用者不一定知道,但結果品質已經不對了。
分析:為什麼這問題被低估
技術面的原因很直接:token budget 問題在 demo 裡不會出現。
你做一個 demo,任務規模小、context 乾淨、happy path 跑完,一切都很漂亮。問題是企業真實環境的任務複雜度跟 demo 差了好幾個數量級。Morgan Stanley 的 codebase 跟你 hackathon 的 side project 不是同一個宇宙的東西。
這讓我想到當年 microservices 剛流行的時候,大家都在聊分散式架構的好處,很少人提 distributed system 的除錯有多痛。等到真的在生產環境跑起來,才發現 network partition、latency、service discovery 這些問題才是大魔王。Token budget 問題有點類似的形狀——它是 agentic system 的「distributed system 除錯問題」,在複雜度夠高之前你感覺不到它的存在。
商業面的問題更有趣。目前大部分 AI agent 公司的商業模式還在早期,很多是用 per-seat 或 per-task 收費,token 成本內化在自己身上。這讓他們有很強的動機去解決 token efficiency 問題,但不一定有動機把這個問題公開說清楚——因為說清楚了,客戶就會問「那你們怎麼控制?保證不超多少 token?」這是一個很難 commit 的承諾。
Factory 選擇把 model 選擇抽象化(Matan 提到 Factory 押注 model independence),部分原因就是不同 model 在 token efficiency 上有很大差距(來源:The Generalist,timestamp 20:10)。同樣的任務,用不同 model 跑,token 消耗可以差很多。如果你的系統深度綁定某個 model,你的 token budget 問題就更難解。
Waiting7777
WoW Arena 冠軍轉前端,用電競 meta 思維拆解技術趨勢。

這篇文章對你有幫助嗎?
每週一篇 — 技術趨勢背後的商業邏輯
AI 產業在變什麼、工程師該注意什麼——拆清楚寄到你的信箱。