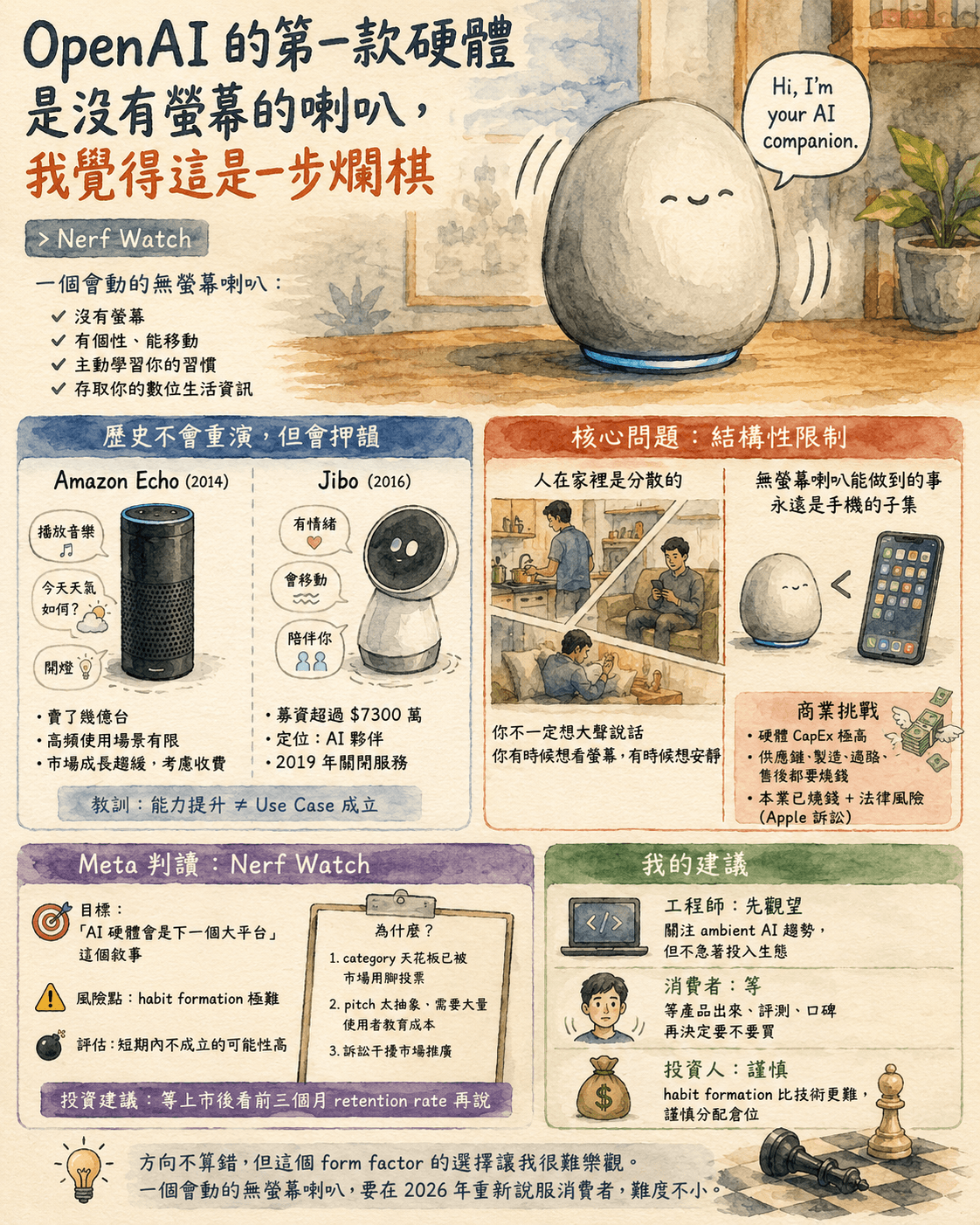
← 所有文章前幾天我把自己的網站 bridge-craft.org 拿去 isitagentready.com 掃了一下。結果:9 項檢查,全部 fail。
說實話我不意外。這些檢查不是 SEO,也不是 accessibility,而是「AI agent 能不能讀懂你的網站」。2026 年了,agent 爬網站已經是常態,但多數個人網站(包括我的)還是按 human + Googlebot 的思路在做。
這篇記錄我把 9 項全部補完的過程:做了什麼、為什麼這樣做、踩到哪些坑。重點不是炫技,如果你也想讓自己的網站對 agent 友善,這些是最低限度。
背景:agent 在意什麼
對一個 AI agent 來說,它到一個網站的第一件事通常是:
- 這個站提供什麼 API?
- 要怎麼驗證?
- 有沒有結構化的「功能清單」可以直接呼叫?
- 文章能不能用 markdown 給我,不要一坨 HTML?
- 網站 owner 對於 AI 訓練 / 搜尋 / 推論有什麼偏好?
這些在 SEO 年代沒人在意,但現在都陸續有了 RFC 和 well-known 路徑。我要補的 9 項對應到:
- RFC 8288 — Link headers
- Markdown for Agents — content negotiation
- Content Signals — robots.txt
- RFC 9727 —
/.well-known/api-catalog
- RFC 8414 / OIDC Discovery —
/.well-known/oauth-authorization-server、/openid-configuration
- RFC 9728 —
/.well-known/oauth-protected-resource
- SEP-1649 — MCP Server Card
- Agent Skills Discovery RFC —
/.well-known/agent-skills/index.json
- WebMCP —
navigator.modelContext.provideContext()
一個個來。
最便宜的一項。next.config.ts 裡針對 source: "/" 加一組 Link header:
{
source: "/",
headers: [{
key: "Link",
value: [
'</.well-known/api-catalog>; rel="api-catalog"',
'</.well-known/agent-skills/index.json>; rel="agent-skills"',
'</.well-known/mcp/server-card.json>; rel="mcp-server-card"',
'</sitemap.xml>; rel="sitemap"',
'</feed.xml>; rel="alternate"; type="application/rss+xml"',
].join(", "),
}],
}
關鍵:只加在 /,不要放全站,不然每個 response 都多 300 bytes header,沒意義。
2. Markdown for Agents — 同一個 URL,agent 拿 markdown,瀏覽器拿 HTML
概念是:Accept: text/markdown 來的給 markdown,text/html 來的給 HTML。
分兩步:
Step 1 — 新增 app/blog/[slug]/md/route.ts,用 title / published_at 等欄位組 frontmatter + 內文,回 Content-Type: text/markdown; charset=utf-8,順便帶 (body 字數)方便 agent 估 context 大小。
Waiting7777
WoW Arena 冠軍轉前端,用電競 meta 思維拆解技術趨勢。
這篇文章對你有幫助嗎?
每週一篇 — 技術趨勢背後的商業邏輯
AI 產業在變什麼、工程師該注意什麼——拆清楚寄到你的信箱。
x-markdown-tokens
Step 2 — middleware.ts 最前面加一段 Accept-header rewrite:
const accept = request.headers.get("accept") ?? "";
const prefersMarkdown = /text\/markdown/i.test(accept)
&& !/text\/html/i.test(accept.split(",")[0] ?? "");
if (prefersMarkdown
&& /^\/blog\/[^\/]+$/.test(url.pathname)
&& !url.pathname.endsWith("/md")) {
const rewritten = url.clone();
rewritten.pathname = `${url.pathname}/md`;
return NextResponse.rewrite(rewritten);
}
這段一定要放在 Supabase auth 之前。不然每個 agent 讀文章都會觸發一次 session refresh,多一次 DB round-trip,而且 agent 本來就不該用 session 存取。
中間踩了個坑:第一版只靠 regex specificity 擋 /md 路徑,reviewer 提醒我「regex 哪天改寬就是 rewrite loop」。補上 !url.pathname.endsWith("/md") 守衛和測試。
3. Content Signals — robots.txt 告訴 agent 你的偏好
原本 app/robots.ts 用 Next.js 的 MetadataRoute 寫,但它不支援自訂行。改成 app/robots.txt/route.ts 手動組字串:
User-agent: *
Allow: /
Disallow: /admin/
Disallow: /api/
Disallow: /favorites/
Content-Signal: ai-train=no, search=yes, ai-input=yes
Sitemap: https://bridge-craft.org/sitemap.xml
ai-train=no — 別拿我的內容訓練模型search=yes — 搜尋引擎可以ai-input=yes — agent 即時讀取來回答使用者問題可以(inference,不是訓練)
比「allow all / disallow all」細多了。
4. API catalog — linkset 讓 agent 看到你的 API 地圖
/.well-known/api-catalog 回 application/linkset+json(RFC 9264 格式):
{
"linkset": [
{
"anchor": "https://bridge-craft.org/api/labs/paper-whisperer",
"service-doc": [{ "href": "https://bridge-craft.org/labs/paper-whisperer" }],
"status": [{ "href": "https://bridge-craft.org/api/health" }]
}
]
}
每個 anchor 是一個 API 根,下面列 service-desc(OpenAPI)、service-doc(人看的文檔)、status(健康檢查)。
我原本偷懶,把 /feed.xml 和 /sitemap.xml 也塞進 linkset,service-doc 指到 /about。reviewer 抓:/about 不是 feed 的文檔,這樣填誤導 agent。移掉。
教訓:不確定 rel 值要指什麼的時候,寧可不填。
5 & 6. OAuth / OIDC discovery — 把 Supabase 的 issuer 曝出來
這兩個一起講。我不自己跑 OAuth server,Supabase 就是我的 AS。所以:
/.well-known/oauth-authorization-server — 返回 Supabase 的 issuer、authorization_endpoint、token_endpoint、jwks_uri、supported grant types/.well-known/openid-configuration — 純 re-export:export { GET } from "../oauth-authorization-server/route";(OIDC metadata 是 OAuth metadata 的 superset,我這個情境下兩者一樣)/.well-known/oauth-protected-resource — 告訴 agent:「這個站是 resource,token 要去 Supabase 拿」
這樣 agent 要呼叫我有 auth 的 API 時,可以程式化發現怎麼認證,我不用寫文檔解釋。
7. MCP Server Card — 預告 MCP endpoint
{
"serverInfo": { "name": "bridge-craft", "version": "0.1.0" },
"transport": { "endpoint": "https://bridge-craft.org/api/mcp" },
"capabilities": {
"tools": { "listChanged": false },
"resources": { "listChanged": false, "subscribe": false }
}
}
/api/mcp 本身是 stub(回 status: "planned" + 三個 plannedTools 名單),但 card 先存在就夠了 — agent 可以先發現、先記錄,等真正的 MCP server 上線再打。
檔名路徑是 app/.well-known/mcp/server-card.json/route.ts,.json 是 URL segment 的 literal 一部分,Next.js 不會因為副檔名做任何特殊處理。第一次看會覺得怪,跑起來就是對的。
8. Agent Skills index — 帶 sha256 指向真實 SKILL.md
/.well-known/agent-skills/index.json 列出這個網站公開的 skills。每個 entry 需要 url 和 sha256(file digest,用來確認 agent 拿到的 SKILL.md 沒被中途改過):
const skillBytes = readFileSync(
path.join(process.cwd(), "public", "skills/paper-whisperer/SKILL.md")
);
const skillSha256 = createHash("sha256").update(skillBytes).digest("hex");
這段 module-scope 的 readFileSync 會在 server 啟動時跑一次;force-static route 則會在 build time 算一次,digest 直接烤進 static response。如果 SKILL.md 改了,下次 build 才更新 — 這就是我要的,agent 拿到的 sha256 永遠對得上當下 deploy 的版本。
內容是一個真的 SKILL.md,講 paper-whisperer 的三步呼叫:session → ingest → chat。
部署時有個小陷阱:Next.js output: "standalone" 不會自動 copy public/,Dockerfile 要自己 COPY --from=builder /app/public ./public。我事先檢查過,好在原本就有這行。
9. WebMCP — 給瀏覽器裡的 agent 一組可呼叫工具
最未來感的一項。WebMCP 讓 browser agent(Arc、Chrome 內建那種)透過 navigator.modelContext 發現頁面提供的 tools。
"use client";
export default function WebMCPProvider() {
useEffect(() => {
if (typeof navigator === "undefined") return;
if (!("modelContext" in navigator)) return;
(navigator as NavigatorWithModelContext).modelContext
?.provideContext({
tools: [
{
name: "navigate_to_blog",
description: "Open the blog index page.",
inputSchema: { type: "object", properties: {}, additionalProperties: false },
execute: () => { window.location.href = "/blog"; },
},
// navigate_to_paper_whisperer, open_contact ...
],
});
}, []);
return null;
}
掛在 root layout,沒有 modelContext 就安靜不做事。不支援的瀏覽器(目前幾乎全部)完全無感。
測試時發現一個細節:Vitest 的 jsdom 環境下 navigator 是 getter,不能直接 navigator.modelContext = spy,要用 Object.defineProperty。索性把 register 邏輯抽成 pure helper registerWebMCPTools(nav, tools),測試直接呼叫它,不 mount component、不裝 @testing-library/react。
開發流程:9 個任務用 subagent-driven 跑
這次我沒坐那邊從上寫到下。先寫了 docs/plans/2026-04-19-agent-friendly-site.md 把 9 個任務拆成 TDD 規格,每個任務寫清楚要開哪些檔、測什麼、預期 output。然後用 superpowers 的 subagent-driven-development skill 跑:
- 每個任務派一個 implementer subagent
- 做完派 spec reviewer 查「有沒有完全照規格做」
- 再派 code quality reviewer 查「code 本身有沒有問題」
- 兩關都過才進下一個任務
好處是每個 subagent 的 context 是乾淨的,不會被前面任務的雜訊汙染。壞處是 review 會抓出很多 nit,修了再 review 又一輪 — 但每次修的都是對的修,長期品質會收斂。
9 個任務裡:Task 2 被抓到 rewrite loop 風險;Task 4 被抓到 service-doc 亂填;Task 7 被抓到 card 字段比 spec 多。全部是我自己讀不會發現的。
幾個一致性的小決定
跑完之後回頭看,有幾個 cross-cutting 決策值得記:
export const dynamic = "force-static" — 所有 discovery routes 都 static,build 時算好。- 不要再寫
export const revalidate = N — 在 force-static 下是 dead code。我一開始寫了,reviewer 第二次就抓,後面全部拔掉。
cache-control: public, max-age=3600, s-maxage=3600 一致,CDN 和 browser 都快取一小時。- Origin 一律從
process.env.NEXT_PUBLIC_SITE_URL 推,fallback https://bridge-craft.org。不在 route 裡硬寫。
- Route 檔名
foo.json/route.ts — 副檔名是 URL 的一部分,不是檔案類型。
這些小事單獨看都沒什麼,但 9 個 routes 全部不一致的時候,半年後 debug 會瘋掉。
沒做、不做的事
/api/mcp 真正能跑的 MCP server — 先發 card + stub,等我想清楚要曝哪些 tools 再補(大概是 list_posts / get_post / search_posts)。- JWKS 自己 host — 我沒自己簽 token,Supabase 幫我簽,
jwks_uri 直接指回 Supabase。
- WebMCP 動態 tools — 現在是靜態 3 個 navigation tools,未來可以按頁面加(例如在 blog post 頁加「訂閱 RSS」tool)。
總結
9 個任務、一個週末、14 個 commits。實際寫 code 4-5 小時,剩下都在讀 RFC、對 spec、改 review 抓到的問題。
- 先跑 isitagentready.com 看你缺什麼
- 從最便宜的補起:Link headers → robots.txt Content-Signal → markdown negotiation
- well-known JSON routes 一起做(共用 force-static + cache-control 樣板)
- WebMCP 放最後,現在還沒什麼 browser agent 真的吃得到
不用一口氣全做,但至少 1/2/3 那三個,今天就可以上。
Agent 正在變成網站的第二類訪客。SEO 花了 20 年才變成常識,agent-friendly 可能不用那麼久。
市場分析
投資
Q2 2026
VC
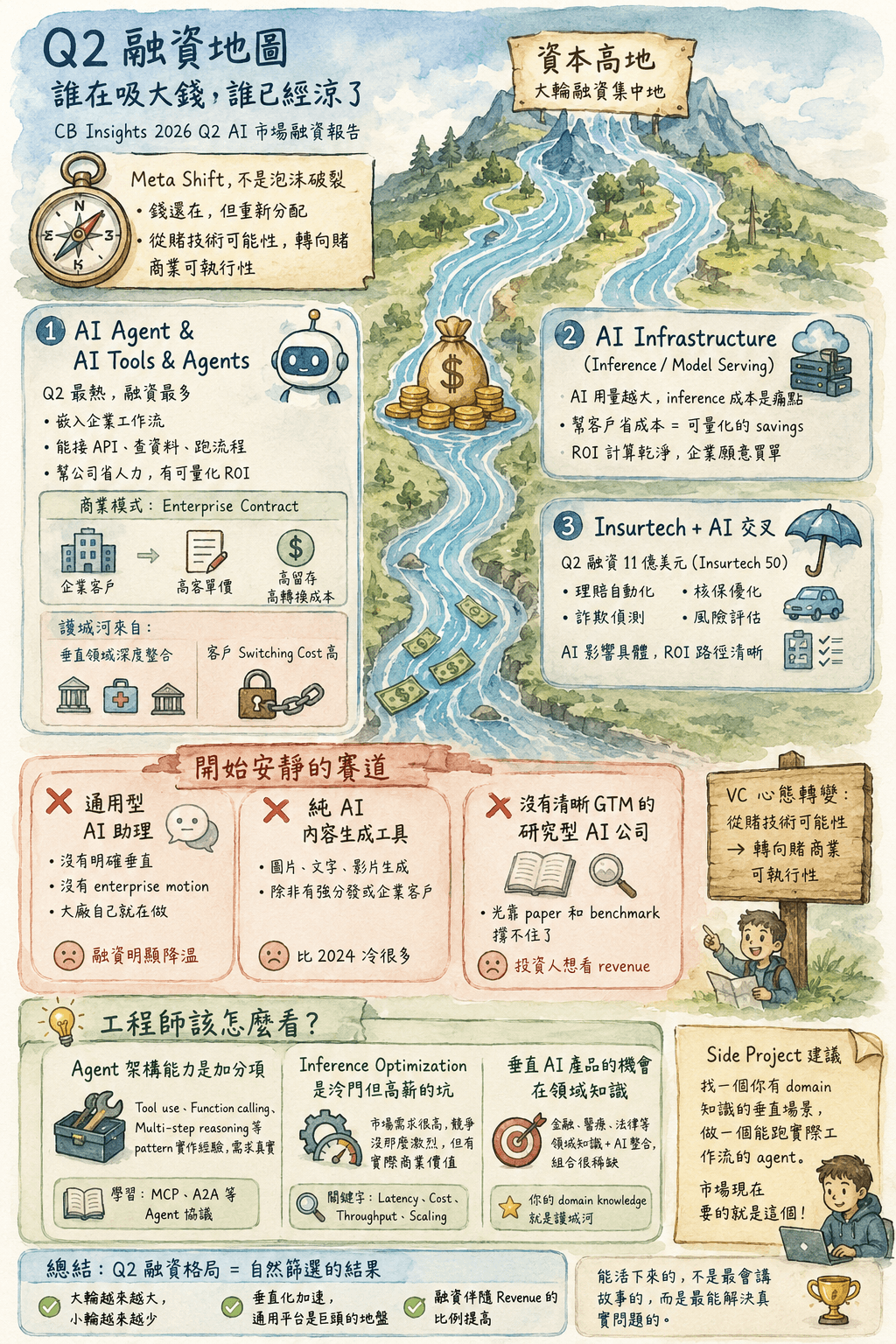
Q2 2026 AI 融資全景:哪些賽道還在吸大錢、哪些已經冷掉了
從 Q2 融資數據找 pattern — 哪些 AI 賽道還在吸引大錢、哪些已經冷掉,用投資人的錢去向來判斷產業真實走向。
2026年7月14日 · Waiting7777 · 7 分鐘閱讀
繼續閱讀 →